
Hogyan működnek az LSTM-modellek?
Az LSTM, azaz Long Short-Term Memory (~hosszú rövidtávú memória) nem mai csirke (az eredeti kutatás 1997-ben jelent meg), ráadásul elég sokáig csendesen bujkált: egészen 2014-ig kellett várni, hogy berobbanjon a köztudatba, amikor is Cho és munkatársai előálltak egy egyszerűsített modellel (ez volt a GRU, és nem, nem a minyonos fajta), egy évre rá viszont már a Google is elkezdte használni a Google Voice-ban beszédfelismerésre.
Ennek ellenére fontosnak tartom megmutatni, hogy hogyan működik, hiszen nagy előrelépés volt a szekvenciális adathalmazokkal való munkában, ráadásul a manapság méltón sikeres transzformer-modellek is lényegében az LSTM és ehhez hasonló (enkóder-dekóder-alapú) modellek hibáit próbálják kiküszöbölni.
Az LSTM egy rekurrens neurálisháló-architektúra, amely az egyszerű feedforward hálózatokkal szemben feedback-kapcsolatokkal is rendelkezik. Nem csak egy adatpontot (pl. egy képet) tud feldolgozni egyszerre, hanem szekvenciákat, sorozatokat is értelmezni tud (pl. mondatok, videók, beszéd).
Ha valaki olvasott már rekurrens neurális hálókról (RNN), megfordulhat a fejében – de hiszen már az RNN-ek is tudtak szekvenciális adatokkal dolgozni, ráadásul ott is hatással lehetnek a korábbi megfigyelt adatpontok az épp aktuálisan megfigyelt pontra, minek túlbonyolítani?

Letisztult, szép, egyszerű… Minek piszkálni?
A színre lép: az eltűnőgradiens-probléma
Ez a probléma alapvetően jelen van szinte mindenhol, ahol mély neurális hálókat használunk gradiens-alapú tanulási módszerekkel és backpropagation-nel (erre tudtok rendes magyar kifejezést amúgy? Visszaterjesztés mondjuk?). Ezeknél a módszereknél ugye a neurális háló súlyait a hibafüggvénynek az aktuális súlyhoz viszonyított parciális deriváltjával arányosan frissítjük a tréning minden egyes iterációjában. A probléma az, hogy egyes esetekben a gradiens olyan kicsi lesz, hogy (szinte) eltűnik.
A gradiens ugye megmutatja, hogy milyen irányba lejt a hibafüggvény, és ebbe az irányba lépegetünk azért, hogy haladjunk az egyre kisebb hiba felé. Viszont, ha a gradiens pici, vagy nulla, akkor hiába futtatjuk a tanítást, a modell alig, vagy egyáltalán nem lép a kisebb hiba irányába, azaz nem tanul. Például, ha a hiperbolikus tangenst vesszük aktivációs függvénynek, amelynek a gradiensei -1 és 1 közt vannak, a láncszabály szerint a backpropagation során n darab ilyen kis számot szorzunk össze ahhoz, hogy egy n-rétegű neurális háló első pár rétegének súlyait frissítsük. A gradiens ilyenkor exponenciálisan csökken n-el, és az első rétegek nagyon lassan tanulnak. Magyarul: az RNN-nek túl rövid lesz a memóriája, és a később látott adatokból több mindenre fog emlékezni, mint a korábban látottakból.
Erre a legegyszerűbb megoldás nem-rekurrens hálóknál az, ha olyan aktivációs függvényt használunk, aminek nem kicsik a deriváltjai, mint pl. a ReLU. RNN-eknél viszont ez nem szolgál 100%-os megoldással, mert nem csak az aktivációs függvény miatt tűnhetnek el a gradiensek, hiszen a rejtett állapot (hidden state, erről később) deriváltja a súlyokon is múlik. Ráadásul minél mélyebbre megyünk a rekurrenciával, a ReLU használatával annál nagyobb lesz az esélye az ellenkező problémának, hogy a gradiensek „felrobbannak”, azaz túl nagyok lesznek.
Az LSTM-architektúra tehát pontosan erre a problémára kínál megoldást.
Kapuk, kapuk mindenhol
Az LSTM alapfelépítése hasonló az RNN-hez, itt is egymás után ismétlődő modulokból épül fel a rendszer. A különbség az, hogy míg az RNN-ek esetén az egyes modulokban valamilyen egyszerű struktúrát találunk, például egy tanh réteget, az LSTM-eknél egy komplex, több kapuból álló rendszert találunk.

A sárga négyzetek neurálisháló-réteget, a piros karikák valamilyen pontonkénti műveletet, a nyilak vektorátadást, vonalak találkozása konkatenációt, szétválása másolást jelent.
Az LSTM-ek fő komponense a cellastátusz, amely az egész láncon végigmegy, és csak kisebb lineáris változtatások történnek rajta. Az LSTM képes hozzáadni vagy elvenni információt a cellastátuszhoz/tól, ezt pedig kapuk segítségével teszi.

A cellastátusz végigmegy az egész láncon, cellánként frissül(het)
A kapuk segítségével bizonyos feltételekkel tudunk információt átengedni. Ezek a kapuk egy szigmoid rétegből és egy pontonkénti szorzásból állnak. A szigmoid réteg valamilyen 0 és 1 közti számot ad vissza, ami lényegében azt jelzi, hogy mennyit engedjünk át a kapun a bejövő információból (0 – semennyit, 1 – mindent, plusz bármi a kettő közt). Minden cellának egy LSTM-modellen belül 3 ilyen kapuja van.

Ez még az egyszerűbb része a dolognak!
A celláknak 2 bemenete és 2 kimenete van, egyrészt megkapják az előző, Cₜ₋₁ cellastátuszt, valamint az előző cella hₜ₋₁ outputját, másrészt, miután frissítik a cellastátuszt és kiszámolják a saját kimenetüket, azokat továbbadják a következő cellának.
Vegyük példának, hogy a „A piros autó szélsebesen suhant végig a városon”, és az LSTM-ünket arra akarjuk megtanítani, hogy kiegészítse a „A ……. színű ……. rendkívül ……. haladt” mondatot. Ehhez az LSTM a cellastátuszban letárolhatta például a „piros”, „autó” és „szélsebes” szavakat.
Amikor viszont bejön az új bemenet, például „A zöld autó ősöreg volt és szörnyen lassan döcögött”, az első lépés, hogy kiszámoljuk, mit szeretnénk elfelejteni – ez a 3 közül az első, úgynevezett felejtés-kapu. A példánkban ezen a ponton már nem releváns a „piros”, sem a „szélsebes”, ezért ezeket a kifejezéseket el kell felejteni. A felejtés-kapu az előző cella kimenete és az új input alapján kiszámolja, hogy mit kell elfelejtenie a cellastátusznak:

“f“, mint “forget“
A következő kérdés, hogy mi az, amit meg szeretnénk jegyezni, azaz mi az, amit el szeretnénk menteni a cellastátuszba. Itt először egy szigmoid réteg – amit inputkapu-rétegnek nevezünk – eldönti, hogy mely értékeket kell frissíteni és mennyire (iₜ; ahogy fentebb is írtam, a kapuk működéséből kifolyólag a felejtés és az input sem végletekben működik, tehát nem csupán „vagy teljesen elfelejtem, vagy teljesen megjegyzem” lehetőségeink vannak, hanem egy 0-1 közti skálán kapjuk meg, hogy „mennyire” kell elfelejteni, vagy megjegyezni valamit). Azáltal, hogy 0 és 1 közé vetít mindent, azt mondja, hogy ahol nulla van, az nem fontos, ahol 1, az meg nagyon. Ezután egy tanh réteg az előző rejtett státusz és az új input alapján legenerálja az új, lehetséges értékeket, amiket hozzáadhatunk majd a cellastátuszhoz (és a [-1,1] közé szorítás által regularizál). Lényegében az inputkapu eldönti, hogy az előző rejtett státuszból és az új adatból mi az, amit hozzá kell adni a cellastátuszhoz. A kettőt összeszorozva megkapjuk az inputkapu kimenetét. Ez lényegében azt adja meg, hogy az előző rejtett státuszból és az új adatból mit és „mennyire” kell hozzáadni a cellastátuszhoz. Ennek a szorzatnak az eredményei a lehetséges új értékek aszerint súlyozva, hogy azok mennyire fontosak.

Az inputkapu eldönti, hogy mi és mennyire fontos a rejtett státusz (~az előző cella outputja) és az új input alapján
Most tehát ott tartunk, hogy a felejtés-kapu eldöntötte, mit kéne elfelejteni, az input-kapu pedig eldöntötte, hogy melyik értékeket szeretnénk hozzáadni a cellastátuszhoz milyen súlyozással. A következő lépés az lesz, hogy ténylegesen frissítjük is a cellastátuszt ezek alapján az eredmények alapján.
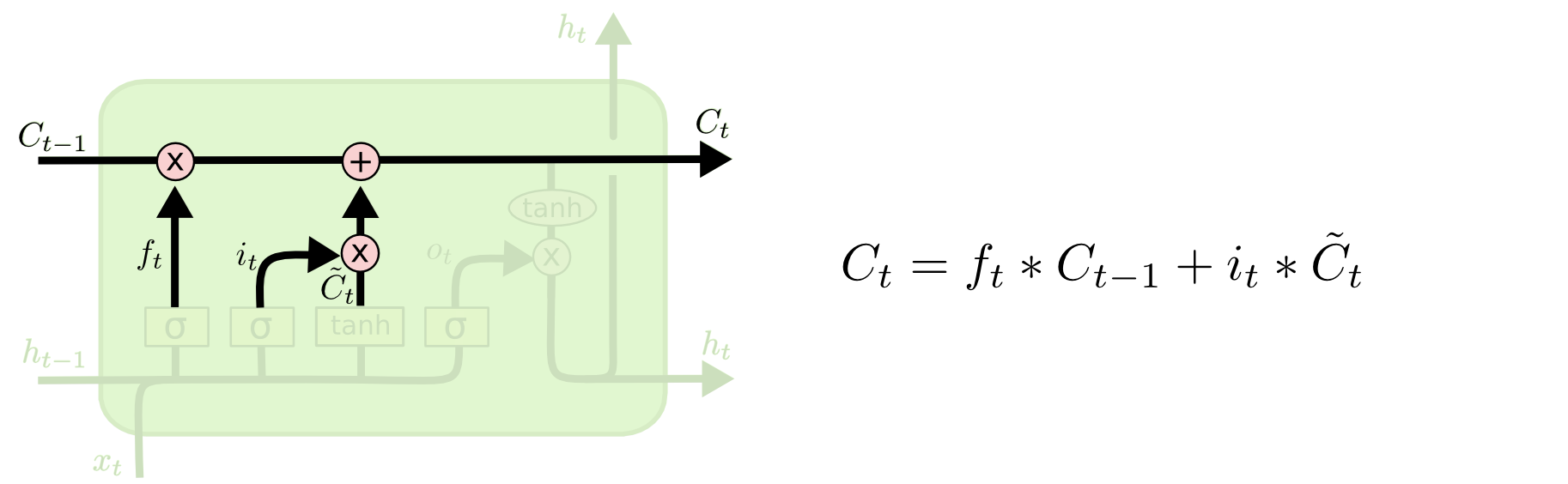
Megtesszük végre, amit kiszámoltunk, hogy meg kell tenni!
Az előző cellastátuszt megszorozzuk az fₜ függvénnyel, ezzel a cellastátusz ténylegesen elfelejti, amit a felejtés-kapu kiszámolt, hogy el kell felejteni. Ezután a cellastátuszhoz hozzáadjuk azokat az értékeket, amikről az input-kapu eldöntötte, hogy meg kell jegyezni. A felejtés- és az input-kapuk eredménye például az lehet, hogy ha az előző mondatunkban Erika egy piros autóban gurult az aszfalton, de az újban Árpi egy zöld színű gépjárműben parkolt, akkor itt a felejtés kapu elfelejteti Erikát (szegény Erika), a piros színt meg a gurulást, mert már nem releváns, az input-kapu pedig megadja, hogy fontos lenne megjegyezni a zöld színt, az előző „autó” értéket nem igazán kell megváltoztatni, de adjuk még hozzá a státuszhoz azt is, hogy épp parkolt a gépjármű. Viszont az „egy” meg a „színű” szavak nem relevánsak, azokat nem kell elmenteni a státuszba. Olyanok is történhetnek, hogy pl. elfelejti a státusz az eddig tárolt nemet, vagy, hogy egyes, vagy többes számban beszélünk stb.
A cellastátuszt ezennel módosítottuk, ez így mehet is tovább a következő cellába. Az utolsó lépés az output kiszámolása, ami a cellastátusz filterezett verziója lesz. Először is átengedjük az előző cellából megkapott rejtett státuszt és az ebben a cellában megkapott inputot egy szigmoid rétegen, amely eldönti, mi a legfontosabb információ. Egy tanh segítségével pedig -1 és 1 közé szorítjuk a már frissített cellastátusz-értékeinket. Ezeket összeszorozva megkapjuk az outputot, amit egyrészt továbbadunk a következő cellának, de – architektúrától függően – akár már előrejelzéshez is használhatunk. Ez az utolsó lépés a harmadik, úgynevezett output-kapu.

A hₜ-t ezen a ponton már használhatjuk előrejelzésnek is, ha például valamilyen autoregresszív modellt építünk
Bár ez önmagában is elég absztrakt, és működés közben még sokkal absztraktabb dolgok történnek az egyes cellákon belül, példával körülbelül így tudnám leírni, hogy mi történik:
Tegyük fel, hogy az előző cellastátusz lementette, hogy egyes számról és férfiról van szó, akinek a neve Károly. Az előző mondatban főzés volt említve és valamilyen étel. Az előző cella rejtett státusza valami olyan információt adhat át, ami ennek a kettőnek az ötvözete, tehát, hogy egy férfi valamilyen ételt főzött.
Az új mondatunkban több nő eszik. Ekkor a cellastátusz elfelejti az egyes számot és a férfit (a felejtéskapu ezekre a pontokra nullát, vagy a közeli értéket számolt, és a pontonkénti szorzás eredményeképpen a „szám” és a „nem” helyeken az érték kinullázódik), viszont lementi a többes számot, a nőt és az evést (az input-kapu eredménye a „szám”, „nem” és „tevékenység” helyekre valamilyen egyhez közeli érték, így amit a felejtéskor kinulláztunk, az feltöltődik értékkel, amikor a cellastátuszhoz – ami ugye ezeken a helyeken 0 – hozzáadjuk az input-kapu eredményét), és nem felejti el, hogy volt egy Károly nevű férfi (a „személy” helyen az inputkapu nullát számolt, tehát a Károlyt jelentő értékhez nullát adunk, azaz az érték nem változik).
Az előző rejtett státuszból (egy férfi valamilyen ételt főzött) a mostani új mondattal kombinálva (több nő eszik) a cella úgy dönthet, hogy megtartja az evést és az étel nevét. A jelenlegi cellastátuszból ehhez hozzájön a „több nő”, így az output valami olyasmit fog reprezentálni, hogy több nő bizonyos ételt eszik, emellett pedig a cellastátusz továbbítja, hogy több nőről van szó, de azt sem felejti el, hogy volt egy Károly nevű férfink.
Így, ha aztán kérdések megválaszolására tanítjuk a modellt, a cellastátusz segítségével emlékezni fog arra, hogy a férfit Károlynak hívták, akkor is, ha Károlyról nem volt szó már pár mondat óta. Viszont, ahogy változnak a mondatok, a felejtés- és inputkapuk által alkalmazkodni tud ahhoz is, ha változik az alany, állítmány stb.
Az LSTM-modellek hátrányai
Bár alapvetően az eltűnőgradiens-probléma megoldása volt az LSTM-ek elsődleges célja, a valóságban így sem sikerült tökéletesen kiküszöbölni azt. Emellett pedig iszonyat sokáig tart betanítani egy ilyen modellt, különösen azért, mert a rétegei lineárisan következnek egymás után, és a következő cella az előzőre alapoz, ezért nehéz párhuzamosítani a tanítást, valamint magas a memóriaigénye is egy ilyen modellnek. Ha viszont sikerül elég erős hardware-t találni, a modell hajlamos a túlillesztésre, ráadásul az architektúrája miatt nem egyszerű dropout-ot alkalmazni rajta a regularizációhoz.
Összefoglalva tehát: az LSTM egy olyan modell, amely specializált cellák segítségével próbálja megoldani az eltűnőgradiens-problémát, egy cellán belül 3 kapuval: a felejtés-kapu dönti el, hogy a cellastátusz mit felejtsen el, az input-kapu dönti el, hogy milyen új dolgokat jegyezzen meg, az output-kapu pedig előrejelzéseket továbbít a cellastátusz, az előző cella előrejelzése és az új input alapján.
Bizony ez elsőre (meg másodikra sem) egy egyszerű modell, és manapság inkább van történelmi, mint praktikus jelentősége (hasonló feladatokra szinte minden szempontból jobbak a transzformer-modellek), viszont érdekes betekintést mutat egy újabb olyan módszerbe, ami vagy 20 évvel a kora előtt járt.
Ha bármi kérdésed van, keress bizalommal LinkedIn-en!
Forrás: